

需求分析
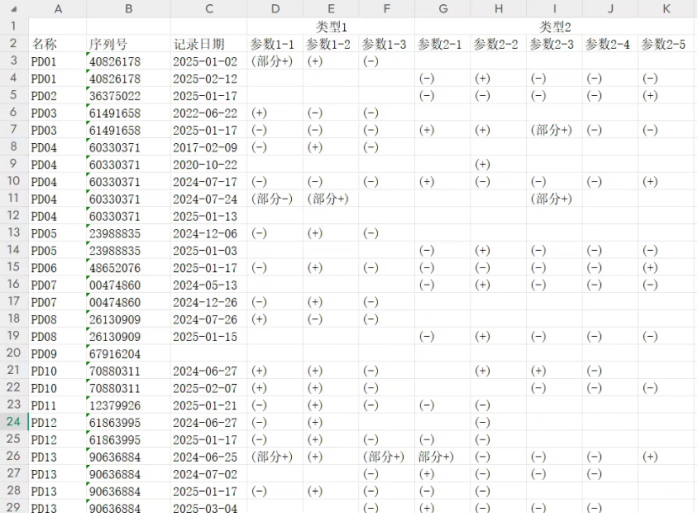
吐槽归吐槽,活始终得干,看一下初始的excel的样子:

类似的“几份”excel放在同一个文件夹下:
按照设备序列号分组,每个设备的信息合并成一行 每个设备的那一行,将记录日期、类型1和类型2中的参数拼接起来 批量处理文件夹下所有excel,命名规则:原文件名_xx年{上个月}月
分步搞
注意
脚本中的两个第三方库,使用前需要安装
pip install pandas openpyxl
不要急着把处理结果发送给可爱的领导
适时告知领导这活可不好干,“尽快”不了
干活中途,多喝水,多走动,多摸鱼
完整代码
# -*- coding: utf-8 -*-
"""
@Time : 2025/8/10 9:30
@Author : 数据处理优化版
@功能说明: 批量处理Excel设备台账,支持按序列号分组合并、自定义表头与输出命名
"""
import datetime
import logging
from pathlib import Path
from typing import Union, List
import pandas as pd
from openpyxl import load_workbook
from openpyxl.styles import Alignment
from openpyxl.workbook.workbook import Workbook
from openpyxl.worksheet.worksheet import Worksheet
# -------------------------- 配置参数(可根据实际需求修改) --------------------------
# Excel结构配置
HEADER_ROW_INDEX = 1 # 列名所在行(原数据第二行,索引从0开始)
DATA_START_ROW = 2 # 数据开始行(原数据第三行,索引从0开始)
GROUP_COL_INDEX = 1 # 分组列(设备序列号,第二列,索引从0开始)
MERGE_SYMBOL = "|" # 多记录拼接符号
# 表头合并配置(行从1开始,列从1开始)
HEADER_MERGE_CONFIG = [
{"start_row": 1, "start_col": 4, "end_row": 1, "end_col": 6, "value": "类型1"},
{"start_row": 1, "start_col": 7, "end_row": 1, "end_col": 11, "value": "类型2"}
]
# 日志配置
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
handlers=[logging.StreamHandler()]
)
logger = logging.getLogger(__name__)
def read_excel_data(file_path: Union[str, Path]) -> pd.DataFrame:
"""
读取Excel文件,提取列名与数据
:param file_path: Excel文件路径
:return: 包含列名与数据的DataFrame
:raises FileNotFoundError: 文件不存在时抛出
:raises Exception: 其他读取错误时抛出
"""
try:
# 读取全部内容(不自动识别表头)
full_df = pd.read_excel(file_path, header=None, engine="openpyxl")
# 提取列名(指定行)与数据(指定行之后)
columns = full_df.iloc[HEADER_ROW_INDEX].tolist()
data_df = full_df.iloc[DATA_START_ROW:].copy()
data_df.columns = columns
# 过滤空行(仅保留至少有一列非空的行)
data_df = data_df.dropna(how="all")
logger.info(f"成功读取文件:{file_path.name},数据行数:{len(data_df)}")
return data_df
except FileNotFoundError:
logger.error(f"文件不存在:{file_path}")
raise
except Exception as e:
logger.error(f"读取文件{file_path.name}失败:{str(e)}")
raise
def merge_device_data(group_df: pd.DataFrame) -> pd.Series:
"""
按设备分组合并数据:前2列取首行,其余列拼接非空值
:param group_df: 单设备的多条记录DataFrame
:return: 合并后的单条记录Series
"""
# 前2列(名称、序列号)取第一行数据
basic_info = group_df.iloc[0, :2].copy()
# 其余列(记录日期、参数)拼接非空值
param_info = group_df.iloc[:, 2:].apply(
lambda col: MERGE_SYMBOL.join(col.dropna().astype(str)),
axis=0
)
# 合并基础信息与参数信息
merged_series = pd.concat([basic_info, param_info])
return merged_series
def process_single_excel(input_path: Union[str, Path], output_path: Union[str, Path]) -> None:
"""
处理单个Excel文件:读取→分组合并→保存
:param input_path: 输入文件路径
:param output_path: 输出文件路径
"""
try:
# 1. 读取数据
data_df = read_excel_data(input_path)
if data_df.empty:
logger.warning(f"文件{input_path.name}无有效数据,跳过处理")
return
# 2. 按设备序列号分组合并
merged_df = data_df.groupby(
data_df.columns[GROUP_COL_INDEX],
sort=False # 保持原数据顺序
).apply(merge_device_data).reset_index(drop=True)
# 3. 保存合并后的数据
merged_df.to_excel(output_path, index=False, engine="openpyxl")
logger.info(f"合并数据已保存至:{output_path.name}")
# 4. 添加合并表头
add_merged_header(output_path)
except Exception as e:
logger.error(f"处理文件{input_path.name}失败:{str(e)}")
raise
def add_merged_header(excel_path: Union[str, Path]) -> None:
"""
为Excel文件添加合并单元格表头(按配置执行)
:param excel_path: Excel文件路径
"""
try:
# 打开工作簿并获取活动工作表
wb: Workbook = load_workbook(excel_path)
ws: Worksheet = wb.active
# 在第一行插入空行(用于放置合并表头)
ws.insert_rows(1, amount=1)
# 配置表头样式(居中对齐)
header_style = Alignment(horizontal="center", vertical="center")
# 按配置合并单元格并写入内容
for config in HEADER_MERGE_CONFIG:
start_row = config["start_row"]
start_col = config["start_col"]
end_row = config["end_row"]
end_col = config["end_col"]
value = config["value"]
# 合并单元格
ws.merge_cells(
start_row=start_row,
start_column=start_col,
end_row=end_row,
end_column=end_col
)
# 写入内容并应用样式
cell = ws.cell(row=start_row, column=start_col, value=value)
cell.alignment = header_style
# 保存修改
wb.save(excel_path)
logger.info(f"成功为文件{excel_path.name}添加表头")
except Exception as e:
logger.error(f"添加表头失败(文件:{excel_path.name}):{str(e)}")
raise
def get_prev_month_info() -> tuple[int, int]:
"""
获取当前时间的上一个月(年,月)
:return: (上一年,上一月)
"""
now = datetime.datetime.now()
if now.month == 1:
return now.year - 1, 12
else:
return now.year, now.month - 1
def batch_process_excel(folder_path: Union[str, Path]) -> None:
"""
批量处理文件夹内所有Excel文件
:param folder_path: 台账文件夹路径
"""
folder = Path(folder_path)
if not folder.is_dir():
logger.error(f"文件夹不存在:{folder_path}")
raise NotADirectoryError(f"无效文件夹路径:{folder_path}")
# 获取上一个月信息(用于输出命名)
prev_year, prev_month = get_prev_month_info()
logger.info(f"批量处理开始,输出文件月份:{prev_year}年{prev_month}月")
# 遍历文件夹内的Excel文件(仅处理.xlsx格式)
excel_files: List[Path] = [f for f in folder.iterdir() if f.suffix.lower() == ".xlsx"]
if not excel_files:
logger.warning(f"文件夹{folder.name}内无.xlsx文件")
return
# 逐个处理文件
for file in excel_files:
# 生成输出文件名:原文件名_xx年xx月.xlsx
output_filename = f"{file.stem}_{prev_year}年{prev_month}月.xlsx"
output_path = file.parent / output_filename
# 处理单个文件
try:
process_single_excel(file, output_path)
logger.info(f"文件{file.name}处理完成,输出路径:{output_path}\n")
except Exception:
logger.error(f"文件{file.name}处理中断,跳过后续步骤\n", exc_info=False)
continue
logger.info(f"批量处理结束!共处理文件数:{len(excel_files)}")
if __name__ == "__main__":
# 台账文件夹路径(可根据实际情况修改)
TARGET_FOLDER = r"C:\Users\Administrator\Desktop\设备台账"
try:
batch_process_excel(TARGET_FOLDER)
except Exception as e:
logger.critical(f"批量处理整体失败:{str(e)}", exc_info=True)大功告成
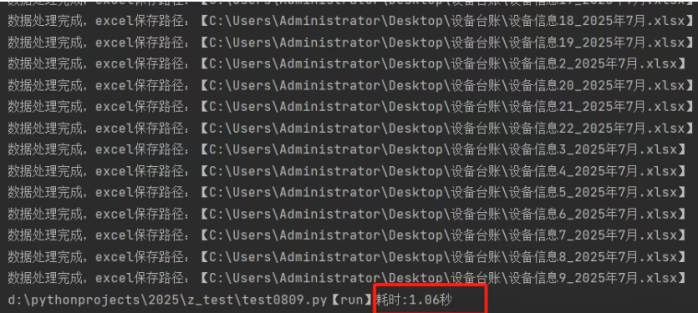
全部实现了前面的几个需求点
处理了20+文件,用时1.06秒
如果是人为手工处理的话,那就是:没有如果!

© 版权声明
文章版权归原作者所有,本站只做转载和学习以及开发者个人原创。声明:下载本站资源即同意用户协议,本站程序仅供内部学习研究软件设计思想和原理使用,学习研究后请自觉删除,请勿传播,因未及时删除所造成的任何后果责任自负。
THE END


















暂无评论内容